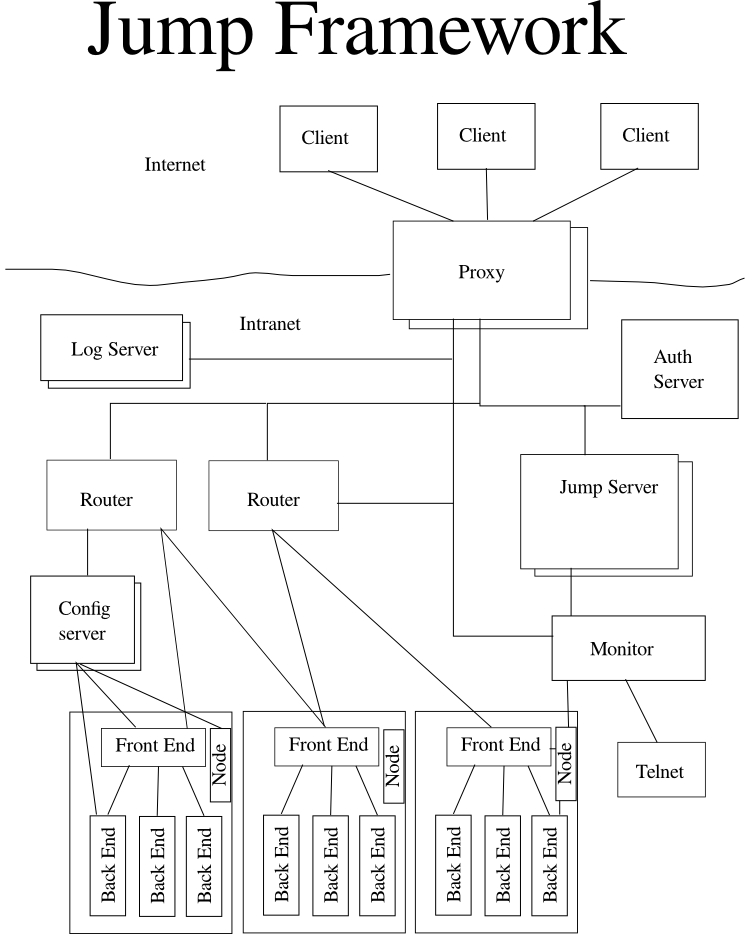
The Jump framework is build on top of libmdw, and allow to easily deploy, maintain, and monitor a complex infrastructure that will handle message processing.
The proxy is the only part of the framework that needs to be in the DMZ. It allows to only show one IP/port to your client. It will also convert any session protocol used by the client (if they don't choose to use the jump protocol) into the jump protocol. You can of course have more than one, for scalability purpose, and has an active/passive achitecture, ie if a daemon fails (crash), then the second will take the role of the first, and create a new passive daemon.
The jump server is a central piece here. When the client connects to the Proxy, the proxy will connect to the jump server. Then, depending on which service the client is requesting, and the global load of the system, the jump server will ask that connection to jump to a specific router. The jump server is also used when an internal service need to connect to another internal service. You can have only one Jump server, but it does also have an active/passive architecture.
The jump protocol is used on top of TCP/IP. It has a fix size format, and gives those services:
As you can only have one Jump server, you don't want to use it for all the traffic of your application. So, when you connect to the Jump server, it will make you bounce to a Router that can route you to the first service you ask for. Then depending on the service, the router will route your message to the a machine that can handle it. If several machines can handle that message, and you don't have any affinity, or context (for instance, a service that will compute the square root of a number), then the router will round robin on all the servers it knows can handle it. If a service need a context (for instance a service that will sum a list of numbers that come in different messages) then it will send all the messages of that subsession into the same machine. If the router sees a message that he does not know to handle, it will jump you back to the jump server, which will jump you to a new Router. If a router think it is too busy, it also may jump you to another router, or to the jump server if it does not know any other router that can handle the current request.
The role of the authentication server is quite simple: authenticate people. Some service may be public, ie used by anybody, anonymously, but some of your services may require the user to authenticate. In that case, if the Router sees that the current message need authentication, it will jump you to the Authentication server, wich will then try to figure who the client is, and then, jump back to the original Router.
The Node is the process used to start any other binary. Basicaly, you must have one running on any machine you want to include in the framework. The first thing that the node will do is to connect to the config server, download the list of process that need to be running on the machine, and start them. It also monitor them, and try to restart any process that fails on the machine. Even it is not represented, a Node process is also present on the machine with the jump server, the proxy, the routers, the log server, the monitor, the authentication server, and even the config server. In the case of a config server node, the node binary has a argument that tells him to start its own config server, locally.
The front end recieve message from the router, and put them in a queue, waiting for any backend to claim them. If a backend that can handle that message is already ready to process, then it will send that message directly to it.
The Backend is the heart of the system, when things happen. When it starts, it tells the local frontend what kind of service it is able to process, and wait until the front end send it a message to process. In the case when several messages are in the same session, then the front-end will try to allways send them to the same backend. If that backend becomes unavailable, it will try to send the next message to another backend. If the new backend accept, and is able to recover the state of the previous backend, then it will process it, and gain ownership of that session. If it cannot handle it, then the session will be considered to be dead, and an error will be reported to the user. If the frontend cannot find another backend to send the message to, the message is sent back to the router, in order to be sent to another machine. If another frontend is found, then same as before, if not, then the connection is sent back to the Jump Server.
The config server contains all the static configuration needed for any binary to start. The ip/port of the config server is given to the arguments of the Node binary. Then, depending of the configuration of the binaries on that machine, every process will connect to its own config server, wich could be the same as the node one. That way, you can have several config servers, and avoid a bottleneck here. Also, every config server has an active/passive achitecture, so that if one crash, it will be automaticaly replaced by its backup. Depending on the configuration, the Config server content can be backed on a file (several csv files, or one xml file) or in a database.
The monitor can connect to any process of the framework, and access internal state of those processes. It also accept a telnet connection, where the system administrator will be able to enter commands, either to view the state of the application, or change the configuration. You can have as many monitor as you want, even if for all practical usage, only one will be needed. In the case of a crash of the monitor, the traffic won't be stopped, so it doe's not need to have an active/passive architecture, it will just be restarted by the local Node process. The only configuration that the monitor needs is the list of all the config servers. Then it will get the list of all the nodes, and from that, the list of all the other process. Most of the commands are routed commands, ie in the form :
nodeName backend type instanceNumber local-commande
The log server is also connected to every process in the framework. More exactly, every process is connected to it. It has 2 roles. First, write to files all the logs of all the processes connected to it, and then, following a set of rules (stored in its config server) may decide to send a mail to a support address on some errors. Every process knows its own log server, so you can have as many as you want. Also, every log server has an active/passive architecture, so if a process fails, its backup will take the ownership of its duties.
